The link between autoregressive models, energy based models and probabilistic language programming
For the past few months I have been thinking about the theoretical foundations of LLM-based agentic systems, or, more precisely, of AI scaffolds: systems in which LLM calls are coupled to tools, control flow, and programmatic runtimes.
In Probabilistic Language Programming, I proposed a first semantics-first vocabulary for these systems through primitives such as sample, factor, and guarantee.
In the current landscape of AI engineering, many scaffolds—Chain-of-Thought, self-consistency, Tree-of-Thoughts, or more elaborate multi-agent setups—are still assembled mostly by intuition and trial and error (Wang et al., 2022) (Yao et al., 2023). The core argument in PLP is that we should stop viewing these workflows anthropomorphically (Meyerson & Qiu, 2025). Persona prompts, plan diversity, or tree search are better understood as probabilistic programs that induce and reweight distributions over execution traces.
In PLP, the LLM supplies an implicit proposal distribution \(\pi_{\mathcal{D}}(\tau)\) for a fixed deployment \(\mathcal{D}\) containing the model, the decoder, the tools, and the rest of the runtime configuration. Programmatic verifiers are encoded by potentials \(\Phi(\tau)\), which assign scores to generated trajectories. The goal of a scaffold is then to sample, as well as possible, from the resulting reweighted target distribution:
\[p_{\mathcal{D}}(\tau) \propto \pi_{\mathcal{D}}(\tau) \Phi(\tau) \tag{1}\label{eq:plp_fundamental}\]The above equation is fundamental in PLP and determines the relation between what we can sample from a prompt \(X \in \mathcal{X}\) and what we think a trace means to our final goal, encoded by \(\Phi(\tau)\).
At that point I thought I had a neat, self-contained systems theory, admittedly still very embryonic: one equation, a few primitives, and a growing intuition that something deeper was hiding underneath.
A few days ago, I stumbled upon a new preprint by (Blondel et al., 2025) “Autoregressive Language Models are Secretly Energy Based Models”. The paper demonstrates a formal bijection between ARMs and Energy-Based Models in function space. The authors prove that the standard autoregressive objective implicitly corresponds to a soft Bellman equation from maximum entropy reinforcement learning. This means that an Autoregressive Model is mathematically an Energy-Based Model that defines a probability distribution over entire sequences. Rather than just predicting the next word, the model is implicitly evaluating an energy landscape over the whole sequence, where lower energy corresponds to a higher overall probability (lower surprise). Because it satisfies the soft Bellman equation, the model possesses an implicit “soft value function”—giving it inherent lookahead capabilities. It’s exactly the soft value function that is important.
The exact mathematical objects I had defined from a top-down, inference-time systems perspective in PLP were perfectly mirrored by their bottom-up, training-time probabilistic graphical models. There is a duality between training time and inference time (as expected) and I wanted to exploit that duality at its best.
Here is the story of how these two theories converge, and what it could mean for the future of agentic systems.
Connecting the dots: proposals, targets, and energies
As a scientist trained in statistical physics, I immediately recognized that proposal and target distributions were not just vaguely reminiscent of probabilistic graphical models. They came with the whole statistical-mechanics vocabulary attached: Boltzmann weights, partition functions, free energy, and approximate marginalization.
In PLP, I define the execution of an LLM workflow as generating a trace \(\tau\) (or also called a trajectory). Running the bare LLM workflow forward induces an implicit generative trace law, the proposal distribution \(\pi_{\mathcal{D}}(\tau)\).
But we rarely want the raw proposal. We usually apply verifiers, tests, or LLM-as-a-judge scorers to filter or rank these traces. These verifier-based potentials are at the core of sampling methods, like rejection sampling or weighted majority sampling: all of them are used a lot in probabilistic programming. I decided to formalize the verifiers as a nonnegative potential function \(\Phi(\tau)\). As in \eqref{eq:plp_fundamental}, the actual goal of any AI compound system is the semantic target, namely the reweighted distribution \(p_{\mathcal{D}}\):
\[p_{\mathcal{D}}(\tau) \propto \pi_{\mathcal{D}}(\tau) \, \Phi(\tau)\]When I opened the Blondel et al. paper, I immediately recognized this equation. They were comparing Autoregressive Models (ARMs)—which make local, next-token predictions—to Energy-Based Models (EBMs), which define globally normalized distributions over whole sequences using a reward/energy function \(R(x, y)\). Here \(R(x,y)\) plays the role of a reward, typically a verifier or scoring function known at training time, that measures whether the answer \(y\) is good for the prompt \(x\).
They note that the optimal solution to MaxEnt reinforcement learning (KL-regularized RL, the basis of RLHF and related alignment methods) takes the form:
\(p^\star(y|x) = \frac{p_{\text{ref}}(y|x) \exp(R(x, y))}{Z(x)}\) where the partition function sums over all possible responses \(y' \in \mathcal{Y}\) and is therefore the intractable object that carries the lookahead.
At that point the dictionary with PLP became impossible to miss. The scaffold proposal plays the role of the reference law, the verifier potential contributes the exponential reward term, and the normalized target becomes the corresponding reference-measure energy-based model.
They were asking:
Can an ARM (our base LLM) learn to perfectly approximate an EBM (our verified target)?
My PLP paper was asking the complementary question:
When an ARM fails to approximate the EBM, how do we use inference-time scaffolding to bridge the gap?
The Secret of the factor Primitive
In PLP, I introduced a primitive called factor(s), which injects heuristic soft scores, for instance a verifier’s confidence, at intermediate steps of a generation trace.
This is exactly the interface used by search procedures that must evaluate partial states before the final answer is known (Yao et al., 2023) (Mo & Xin, 2023) (Zhou et al., 2024).
But I kept wrestling with a deeper question: why are these local heuristics so important for lookahead tasks?
The new paper provides the exact theoretical grounding. Blondel et al. prove a strict bijection in function space between ARMs and EBMs. To convert a global EBM into a local ARM, the local logit score \(q(s_t, y_t)\) must equal the immediate reward \(r(s_t, y_t)\) plus the soft value function of the future, \(V_q(s_t \oplus y_t)\).
\[q(s_t, y_t) = r(s_t, y_t) + V_q(s_t \oplus y_t)\]Where \(V_q\) is the soft value over all future continuations. Originally defined as a log-sum-exp operator, this formulation produces an extensive quantity that accumulates over the sequence, causing a severe length bias. As we will explore in subsequent posts, optimal agentic search replaces this with an intensive MellowMax operator to preserve fair comparisons across sequences of different lengths.
This equation hit me like a ton of bricks.
When we write a PLP workflow and use an LLM critic to evaluate a partial trace, for instance a software architecture plan before writing the code, the factor primitive is fundamentally trying to estimate this intractable soft value function \(V_q\).
Seen this way, a partial-trace critic is not merely judging local plausibility.
It is trying to proxy future verifier-weighted mass.
That observation is also very close in spirit to twisted SMC, where learned twist functions estimate the expected future value of a potential at each step to guide particles toward promising prefixes (Zhao et al., 2024).
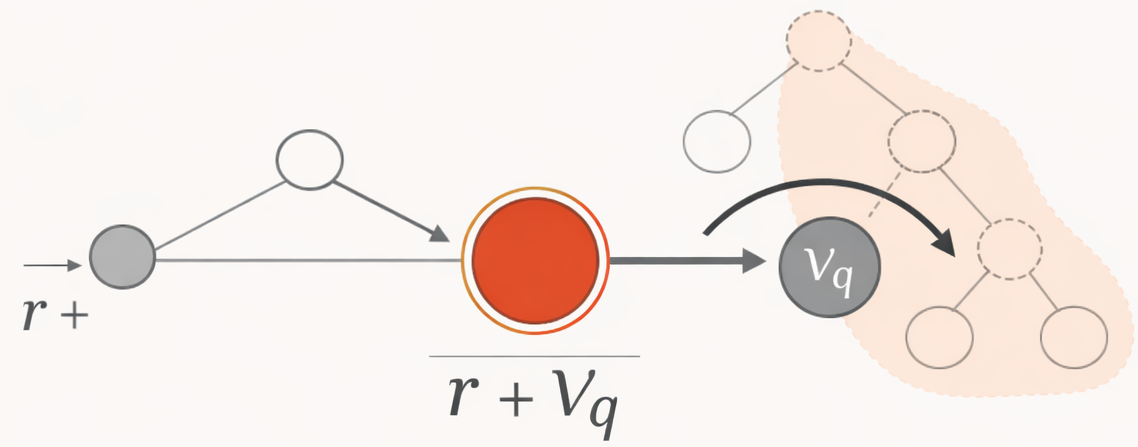
Figure 1. Schematic view of the decomposition \(q(s_t, y_t) = r(s_t, y_t) + V_q(s_t \oplus y_t)\). The immediate local reward is combined with a soft summary of the downstream subtree. The shaded region denotes the set of future continuations whose log-sum-exp contributes to the soft value term.
If our LLMs natively internalized the perfect \(V_q\) during pre-training, they would not need inference-time search at all; greedy decoding would already unroll the target EBM. But finite models struggle to compress the exponential branching structure of \(V_q\) into a single forward pass, which is exactly where the support gap of PLP begins to matter.
Beam search, self-reflection (Shinn et al., 2023), self-backtracking (Yang et al., 2025), and SMC-style steering (Loula et al., 2025) can all be read as numerical attempts to approximate this future term at runtime.
Prompting techniques are ways to approximate an intractable partition function
This immediately raises two questions.
Why don’t we simply
factorall the samples by the \(V_q\) term?
And, more generally, why not introduce these factors through a temperature schedule, as in annealing with an inverse-temperature parameter \(\beta\)?
Statistical mechanics (again)
In the paper, the soft-value function \(V_q(s_t)\) is defined as the log-sum-exp over all possible next tokens. For anyone familiar with statistical physics, this expression is immediately recognizable. If we view the local scores as negative energies, \(V_q\) is exactly the negative of the free energy, where the sum of exponentiated scores represents the partition function \(Z\).
What does the free energy actually represent here, and why does it matter for language models?
In thermodynamics, a system in equilibrium minimizes its free energy. This minimization is a balance between two opposing forces: seeking the lowest energy states (which in our case means finding the highest-reward, most accurate tokens) and maximizing entropy (maintaining a wide diversity of possible states).
When an autoregressive model considers \(V_q\), it is essentially evaluating the negative free energy of all possible future continuations. A high value of \(V_q\), corresponding to low free energy, means that a particular generation branch is favorable. However, because of the log-sum-exp structure, a branch does not score highly just because it contains a single brilliant completion. It also scores highly if it opens up a wide variety of acceptable continuations.
In other words, the free energy measures the robustness of a future path. The model naturally avoids dead-ends or fragile paths where only one highly specific sequence works. Instead, it prefers paths that offer both high rewards and many viable options. The soft value function captures exactly this balance, allowing the model to plan ahead not by committing to a single rigid trajectory, but by moving toward states that keep the generation safe and open.
Chain-of-thought and the partition function
The paper shows that autoregressive models can in principle represent lookahead because each local logit can absorb a future soft value. But the difficult object is not the local softmax denominator itself. Once the vector \(q(s_t,\cdot)\) is available, its normalization is easy to compute. The real difficulty is that each logit \(q(s_t,y_t)\) must already contain the future term \(V_q(s_t \oplus y_t)\), representing an exponentially large set of continuations.
How is this possible without running Monte Carlo rollouts at inference time? Blondel et al. provide a profound answer: teacher-forcing pre-training acts as the backward dynamic programming pass. During pre-training on trillions of tokens, the objective forces the model to solve the dynamic programming problem implicitly. By the time you run a single forward pass at inference time, the final linear layer’s logits already cache the model’s best guess of the future global energy.
This is where chain-of-thought becomes especially interesting. In PLP, I framed it not as anthropomorphic “reasoning” (Lovelace effect (Riedl, 2014)), but as the introduction of a latent state \(Z\) that factorizes the proposal:
\[Z \sim \pi_\theta(\cdot\mid x), \qquad y \sim \pi_\theta(\cdot\mid x, Z)\]That interpretation now has explicit precedent in the literature. CoT has been formalized as latent-variable inference over rationales (Phan et al., 2023) and, more broadly, as an amortized inference problem over intractable posteriors in language models (Hu et al., 2024).
A single chain-of-thought trace does not literally compute the full partition function. It only selects one path through a much larger latent space. But it does something important: it gives the model extra sequential computation. Instead of compressing the whole future tree into one hidden state, the model can build intermediate states that carry provisional constraints, subgoals, or abstractions.
In this sense, CoT helps approximate the future soft value. It makes the marginalization problem easier for a finite model with finite depth. Rather than asking the network to represent the entire log-sum-exp over future branches in one shot, it lets the network unfold part of that computation into the token stream itself.
The statistical-mechanics analogy becomes much stronger once we move from one trace to many traces: self-consistency, beam search, tree search, or verifier-based reweighting. The system is no longer committing to one narrated path; it is trying to marginalize over many latent trajectories. Self-consistency already states this almost verbatim, sampling multiple reasoning paths and selecting the answer by marginalizing them out at the answer level (Wang et al., 2022). More recent methods such as Progressive-Hint Prompting and refined answer distributions can be seen as sequential ways of reshaping that empirical answer law over multiple rounds (Zheng et al., 2023) (Pal et al., 2024).
Because an autoregressive model factorizes the probability of the output \(\mathbf{y}\) token by token, \(p(\mathbf{y} \mid \mathbf{x}) = \prod_{t=1}^{|\mathbf{y}|} \pi(y_t \mid \mathbf{x}, \mathbf{y}_{<t}),\) it is natural to ask whether a better approximation might come from explicitly marginalizing over latent reasoning traces rather than committing to one sampled derivation. In the discrete trace setting, that object is better written as a sum over all possible reasoning paths (a path integral basically):
\[p(\mathbf{y} \mid \mathbf{x}) = \sum_{\mathbf{z}'} p(\mathbf{y} \mid \mathbf{x}, \mathbf{z}') \, p(\mathbf{z}' \mid \mathbf{x}).\]This is much closer to a genuine partition-function calculation, because the relevant object is now a sum over many reasoning paths rather than one verbalized derivation. It also makes it easier to see why several basins of high reward may coexist, and why weighting or resampling them can improve the approximation of the continuation partition function.
Tree-of-Thoughts, Tree of Uncertain Thoughts, and Language Agent Tree Search push exactly in that direction by expanding prefixes, attaching heuristic or uncertainty estimates to partial states, and allocating more compute to promising branches (Yao et al., 2023) (Mo & Xin, 2023) (Zhou et al., 2024). On the explicitly probabilistic side, twisted SMC and related work make the same idea formal by viewing LM steering as sampling from an unnormalized target distribution with future-value estimates used to guide particles (Zhao et al., 2024) (Loula et al., 2025).

Figure 2. Single trajectory vs. swarm marginalization. While standard greedy decoding provides a single point estimate, generating a swarm of latent reasoning paths effectively integrates over the energy basin, better approximating \(V_q\), the continuation partition function of the target distribution.
Chain-of-thought is a device that reshapes the proposal and adds serial compute, making the intractable future term easier to approximate.
When combined with sampling, search, or factor-style reweighting, it becomes a practical approximation to the global mass that an energy-based view would assign to the answer.
Unifying training and inference into one single perspective
Reading this paper clarified the boundary between post-training and inference-time engineering. We are all trying to solve Likelihood-Free Inference (Cranmer et al., 2020) for the same target distribution.

Figure 3. Two routes toward the same target distribution. On the left, training-time distillation tries to absorb the reward or energy field directly into model parameters. On the right, inference-time scaffolds approximate the same target at runtime through search and verifier-based reweighting.
- The alignment perspective (training-time): Researchers use RLHF, DPO, and process-reward models to push the ARM’s proposal \(\pi_{\mathcal{D}}\) as close to the target EBM \(p_{\mathcal{D}}\) as possible. They want to distill \(V_q\) directly into the weights.
- The PLP perspective (inference-time): Because perfect distillation is impossible for long-horizon, high-variance tasks, we must use algorithms (scaffolds) to bridge the remaining gap. We use structural diversification (personas, decompositions) to fix coverage failures, and calibrated judges (Lee et al., 2025) to fix selection failures.
This realization brings immense clarity to AI engineering. You don’t need a heavy agentic scaffold if the ARM has already successfully distilled the EBM for a specific task. But when the task is novel, or requires strict, logic-driven global constraints, the soft Bellman fixed point is too hard for the ARM to memorize. That is when you must drop down into Probabilistic Language Programming, instantiating the EBM at runtime through plate, interact, and factor primitives.
The theory of ARMs and EBMs clarifies the target we are trying to approximate. Probabilistic Language Programming provides the systems vocabulary and the runtime algorithms needed to approximate that target when exact distillation is impossible.
References
- Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., & Zhou, D. (2022). Self-consistency improves chain of thought reasoning in language models. Arxiv:2203.11171.
- Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y., & Narasimhan, K. (2023). Tree of thoughts: Deliberate problem solving with large language models. Arxiv:2305.10601. https://doi.org/10.48550/arxiv.2305.10601
- Meyerson, E., & Qiu, X. (2025). Position: Scaling llm agents requires asymptotic analysis with llm primitives. Arxiv:2502.04358.
- Blondel, M., Sander, M. E., Vivier-Ardisson, G., Liu, T., & Roulet, V. (2025). Autoregressive Language Models are Secretly Energy-Based Models: Insights into the Lookahead Capabilities of Next-Token Prediction. Arxiv:2512.15605. https://arxiv.org/abs/2512.15605
- Mo, S., & Xin, M. (2023). Tree of uncertain thoughts reasoning for large language models. Arxiv:2309.07694, abs/2309.07694. https://doi.org/10.48550/arxiv.2309.07694
- Zhou, A., Yan, K., Shlapentokh-Rothman, M., Wang, H., & Wang, Y.-X. (2024). Language agent tree search unifies reasoning, acting, and planning in language models. Proceedings of the 41st International Conference on Machine Learning, 235, 62138–62160. https://proceedings.mlr.press/v235/zhou24r.html
- Zhao, S., Brekelmans, R., Makhzani, A., & Grosse, R. (2024). Probabilistic inference in language models via twisted sequential monte carlo. Arxiv:2404.17546. https://doi.org/10.48550/arxiv.2404.17546
- Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. Arxiv:2303.11366. https://doi.org/10.48550/arxiv.2303.11366
- Yang, X.-W., Zhu, X.-Y., Wei, W.-D., Zhang, D.-C., Shao, J.-J., Zhou, Z., Guo, L.-Z., & Li, Y.-F. (2025). Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models. Arxiv:2502.04404. https://doi.org/10.48550/arxiv.2502.04404
- Loula, J., LeBrun, B., Du, L., Lipkin, B., Pasti, C., Grand, G., Liu, T., Emara, Y., Freedman, M., Eisner, J., & others. (2025). Syntactic and semantic control of large language models via sequential monte carlo. Arxiv:2504.13139, abs/2504.13139. https://doi.org/10.48550/arxiv.2504.13139
- Riedl, M. O. (2014). The Lovelace 2.0 test of artificial creativity and intelligence. Arxiv:1410.6142.
- Phan, D., Hoffman, M. D., Dohan, D., Douglas, S., Le, T. A., Parisi, A., Sountsov, P., Sutton, C., Vikram, S., & A Saurous, R. (2023). Training chain-of-thought via latent-variable inference. Advances in Neural Information Processing Systems, 36, 72819–72841. https://doi.org/10.48550/arxiv.2312.02179
- Hu, E. J., Jain, M., Elmoznino, E., Kaddar, Y., Lajoie, G., Bengio, Y., & Malkin, N. (2024). Amortizing intractable inference in large language models. Arxiv:2310.04363, abs/2310.04363. https://doi.org/10.48550/arxiv.2310.04363
- Zheng, C., Liu, Z., Xie, E., Li, Z., & Li, Y. (2023). Progressive-hint prompting improves reasoning in large language models. Arxiv:2304.09797, abs/2304.09797. https://doi.org/10.48550/arxiv.2304.09797
- Pal, S., Chételat, D., Zhang, Y., & Coates, M. (2024). Refining answer distributions for improved large language model reasoning. Arxiv:2412.13292, abs/2412.13292. https://doi.org/10.48550/arxiv.2412.13292
- Cranmer, K., Brehmer, J., & Louppe, G. (2020). The frontier of simulation-based inference. Proceedings of the National Academy of Sciences, 117(48), 30055–30062. https://arxiv.org/pdf/1911.01429
- Lee, C., Zeng, T., Jeong, J., Sohn, J.-yong, & Lee, K. (2025). How to Correctly Report LLM-as-a-Judge Evaluations. Arxiv:2511.21140. https://arxiv.org/abs/2511.21140
Let's talk!
I'm Carlo Nicolini — I am interested on the reliability of AI reasoning systems (interpretability, inference-time methods, probabilistic language programming) and on quantitative portfolio optimization (I am a maintainer of skfolio). If you're working on something in these areas and think we might collaborate, chat, discuss, I'm happy to talk about it!
The best way to reach me is on via DM on LinkedIn.